
FullHD X11 desktop performance of the Allwinner A10
This blog post is assuming that you are a happy owner of one of the devices, based on the Allwinner A10 SoC (with a single core ARM Cortex-A8 1GHz). But hopefully the owners of the other low end ARM based devices may also find something interesting here.
There are plenty of user friendly linux distributions available for Allwinner A10 devices (for example, Fedora is a nice one). Basically you just write an image to the SD card, plug a HDMI cable into your TV or monitor, connect a keyboard and a mouse, power the device on. And then a nice GUI wizard guides you through the initial configuration, like setting passwords, etc. A part of the magic, which allows these user friendly distros to just work out-of-the box, is the automatic detection of the monitor capabilities via EDID and setting the preferred screen resolution, suggested by the monitor. Many monitors are FullHD capable, hence you are likely to end up with a 1920x1080 screen resolution. And that's where it may become a challenge for a low end device.
First of all, 1920x1080 screen has 2.25x times more pixels than 1280x720, and the amount of the pixels to be processed naturally affects the performance. So expect 1920x1080 graphics to be at least twice slower than 1280x720 for redrawing anything that covers the whole screen.
But additionally, as part of the monitor refresh, pixels are read from the framebuffer and sent over the HDMI to the monitor 60 times per second. As there is no dedicated video memory for the framebuffer, the screen refresh is competing with the CPU, DMA and various hardware accelerators for the access to the system memory. We can estimate how much system memory bandwidth is wasted for just maintaining the monitor refresh: 1920x1080 * 4 bytes per pixel * 60Hz = ~500 MB/s
And we should double this amount if the system is driving two monitors at once (HDMI and VGA), but the dual monitor support is outside of the scope of this blog post. Anyway, is 500 MB/s significant or not? Allwinner A10 uses 32-bit DDR3 memory, clocked between 360 MHz and 480 MHz (the default memory clock speed is different for different devices). Which means that the theoretical memory bandwidth limit is between 2.9 GB/s and 3.8 GB/s. So in theory we should be perfectly fine?
Synthetic tests for the monitor refresh induced memory bandwidth loss
We can simply try to boot the system with different combinations of monitor refresh rate, desktop color depth and memory clock frequency. Then do the measurements for each with tinymembench and put the results into tables. The performance of memset appears to be the most affected, hence is it the most interesting to observe. There are also "backwards memset" performance numbers for the sake of completeness (it does the same job as memset, but is implemented by decrementing the pointer after each write instead of incrementing it).
| Memory clock speed | ||||||
|---|---|---|---|---|---|---|
| Video mode | 360MHz | 384MHz | 408MHz | 432MHz | 456MHz | 480MHz |
| 1920x1080, 32bpp, 60Hz | 450 MB/s | 480 MB/s | 509 MB/s | 537 MB/s | 556 MB/s | 556 MB/s |
| 1920x1080, 32bpp, 60Hz (scaler mode) | 548 MB/s | 550 MB/s | 554 MB/s | 554 MB/s | 558 MB/s | 558 MB/s |
| 1920x1080, 32bpp, 56Hz | 449 MB/s | 479 MB/s | 510 MB/s | 522 MB/s | 533 MB/s | 812 MB/s |
| 1920x1080, 32bpp, 56Hz (scaler mode) | 514 MB/s | 620 MB/s | 764 MB/s | 769 MB/s | 774 MB/s | 896 MB/s |
| 1920x1080, 32bpp, 50Hz | 449 MB/s | 467 MB/s | 576 MB/s | 815 MB/s | 1041 MB/s | 1122 MB/s |
| 1920x1080, 32bpp, 50Hz (scaler mode) | 759 MB/s | 885 MB/s | 921 MB/s | 964 MB/s | 1018 MB/s | 1130 MB/s |
| 1920x1080, 24bpp, 60Hz | 421 MB/s | 430 MB/s | 842 MB/s | 972 MB/s | 1074 MB/s | 1219 MB/s |
| 1920x1080, 24bpp, 56Hz | 417 MB/s | 860 MB/s | 947 MB/s | 1030 MB/s | 1168 MB/s | 1210 MB/s |
| 1920x1080, 24bpp, 50Hz | 813 MB/s | 887 MB/s | 1023 MB/s | 1180 MB/s | 1247 MB/s | 1252 MB/s |
| Memory clock speed | ||||||
|---|---|---|---|---|---|---|
| Video mode | 360MHz | 384MHz | 408MHz | 432MHz | 456MHz | 480MHz |
| 1920x1080, 32bpp, 60Hz | 688 MB/s | 817 MB/s | 882 MB/s | 883 MB/s | 974 MB/s | 1040 MB/s |
| 1920x1080, 32bpp, 60Hz (scaler mode) | 726 MB/s | 779 MB/s | 882 MB/s | 884 MB/s | 925 MB/s | 1030 MB/s |
| 1920x1080, 32bpp, 56Hz | 769 MB/s | 824 MB/s | 873 MB/s | 947 MB/s | 995 MB/s | 1123 MB/s |
| 1920x1080, 32bpp, 56Hz (scaler mode) | 762 MB/s | 825 MB/s | 874 MB/s | 959 MB/s | 996 MB/s | 1060 MB/s |
| 1920x1080, 32bpp, 50Hz | 763 MB/s | 863 MB/s | 941 MB/s | 1021 MB/s | 1119 MB/s | 1188 MB/s |
| 1920x1080, 32bpp, 50Hz (scaler mode) | 799 MB/s | 887 MB/s | 919 MB/s | 996 MB/s | 1071 MB/s | 1183 MB/s |
| 1920x1080, 24bpp, 60Hz | 819 MB/s | 919 MB/s | 986 MB/s | 1143 MB/s | 1175 MB/s | 1177 MB/s |
| 1920x1080, 24bpp, 56Hz | 856 MB/s | 938 MB/s | 1097 MB/s | 1098 MB/s | 1178 MB/s | 1239 MB/s |
| 1920x1080, 24bpp, 50Hz | 925 MB/s | 983 MB/s | 1060 MB/s | 1144 MB/s | 1182 MB/s | 1263 MB/s |
The "scaler mode" needs an additional explanation. The display controller in Allwinner A10 consists of two parts: Display Engine Front End (DEFE) and Display Engine Back End (DEBE). DEBE can provide up to 4 hardware layers (which are composited together for the final picture on screen) and supports a large variety of pixel formats. DEFE is connected in front of DEBE and can optionally provide scaling for 2 of these hardware layers, the drawback is that DEFE supports only a limited set of pixel formats. All this information can be found in the Allwinner A13 manual, which is now available in the unrestricted public access. The framebuffer memory is read by the DEFE hardware in the case if "scaler mode" is enabled, and by the DEBE hardware otherwise. The differences between DEFE and DEBE implementations of fetching pixels for screen refresh appear to have different impact on memset performance in practice.
One thing is obvious even without running any tests, and the measurements just confirm it: more memory bandwidth drained by screen refresh means less bandwidth left for the CPU. But the most interesting observation is that the memset performance abruptly degrades upon reaching a certain threshold. The abnormally low memset performance results are highlighted red in table 1. But the backwards memset is not affected. There is certainly something odd in the memory controller or in the display controller.
Attentive readers may argue that the same resolution and refresh rate can be achieved using different timings. The detailed modelines used in this test were the following:
Mode "1920x1080_50" 148.5 1920 2448 2492 2640 1080 1084 1089 1125 +HSync +VSync
Mode "1920x1080_56" 148.5 1920 2165 2209 2357 1080 1084 1089 1125 +HSync +VSync
Mode "1920x1080_60" 148.5 1920 2008 2052 2200 1080 1084 1089 1125 +HSync +VSyncEmpirical tests show that in order to have less impact on the memory bandwidth, we need to maximize pixel clock, minimize vertical blanking and select the target refresh rate by adjusting horizontal blanking. That is assuming that the monitor will accept these extreme timings. The "red zones" in table 1 may drift a bit as a result.
Benchmarks by replaying the traces of real applications (cairo-perf-trace)
The numbers in the table 1 look scary, but does it have any impact on real applications in any significant way? Let's try the trimmed cairo traces again to see how it affects the performance of software rendered 2D graphics.
This benchmark is using gcc 4.8.1, pixman 0.30.0, cairo 1.12.14, linux kernel 3.4 with ARM hugetlb patches added. HugeTLB is very interesting by itself, because it provides a nice performance improvement for memory heavy workloads. But in this particular case it also helps to make benchmark results reproducible across multiple runs (the variance is apparently resulting from the difference in physical memory fragmentation and cache associativity effects). The cairo-perf-trace results from the "red zone" seem to be poorly reproducible with the standard 4K pages.
We can't test all the possible configurations, so just need to pick a few interesting ones:
- 1920x1080-60Hz, DDR3 360MHz (default for Mele A2000 HTPC box)
- 1920x1080-60Hz, DDR3 480MHz (default for CubieBoard)
- 1920x1080-50Hz, DDR3 480MHz (CubieBoard, 'disp.screen0_output_mode=1920x1080p50' in the kernel cmdline)
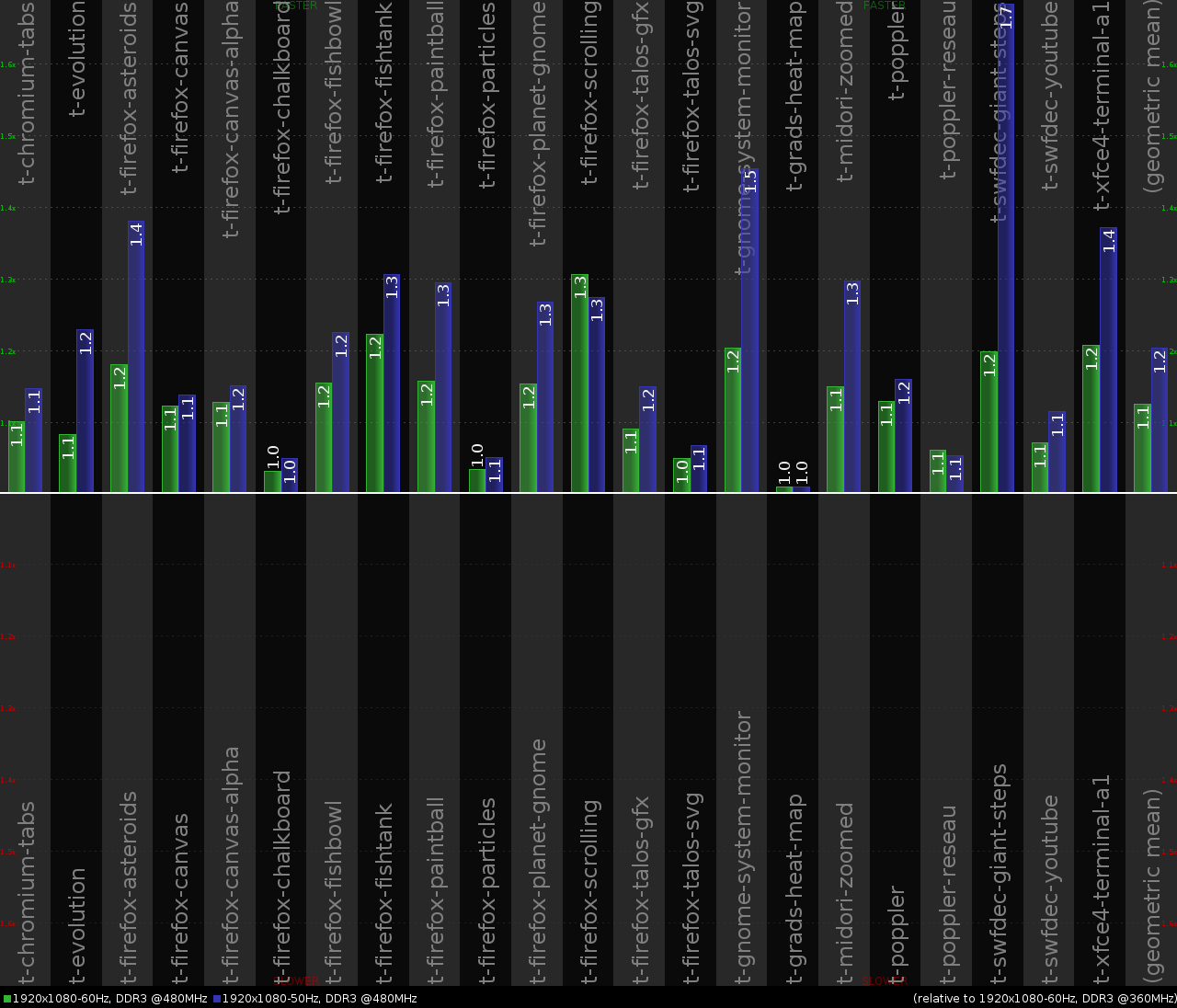
The chart 1 is showing the performance improvements relative to Mele A2000 with its more than conservative default 360MHz memory clock frequency, and using 60Hz monitor refresh rate. The green bars show how much of the performance improvement can be provided by changing the memory clock frequency from 360MHz to 480MHz (by replacing the Mele A2000 with a CubieBoard or just overclocking the memory). The blue bars show the performance improvement resulting from additionally reducing the monitor refresh rate from 60Hz to 50Hz (and thus moving out of the "red zone" in table 1).
The results for the t-swfdec-giant-steps.trace replay show the biggest performance dependency on the monitor refresh rate, so it definitely deserves some profiling. Perf reports the following:
59.93% cairo-perf-trac libpixman-1.so.0.30.0 [.] pixman_composite_src_n_8888_asm_neon
14.06% cairo-perf-trac libcairo.so.2.11200.14 [.] _fill_xrgb32_lerp_opaque_spans
10.20% cairo-perf-trac libcairo.so.2.11200.14 [.] _cairo_tor_scan_converter_generate
3.35% cairo-perf-trac libcairo.so.2.11200.14 [.] cell_list_render_edge
0.82% cairo-perf-trac libcairo.so.2.11200.14 [.] _cairo_tor_scan_converter_add_polygonBingo! Most of the time is spent in 'pixman_composite_src_n_8888_asm_neon' function (solid fill), which is nothing else but a glorified memset. No surprises that it likes the 50Hz monitor refresh rate so much.
An obligatory note about HugeTLB (and THP) on ARM
The chart 1 lists the results with a more than a year old set of HugeTLB patches applied, but this feature has not reached the mainline linux kernel yet. I'm not providing a separate cairo-perf-trace chart, but the individual traces are up to 30% faster when taking HugeTLB+libhugetlbfs into use. And the geometric mean shows ~10% overall improvement. These results seem to agree with the reports from the other people.
Let's hope that ARM and Linaro manage to push this feature in. The 256 TLB entries in Cortex-A7 compared to just 32 in Cortex-A8 look very much like a hardware workaround for a software problem :-) But even older processors such as Cortex-A8 still need to be fast.
Update: turns out that the significantly better benchmark results can't be credited to the use of the huge pages alone. The "hugectl" tool from libhugetlbfs overrides glibc heap allocation and by default does not ever return memory to the system. While heap shrink/grow operations performed in normal conditions (without hugectl) are not particularly cheap in some cases. In any case, the primary purpose of using huge pages via hugectl was to ensure reproducible cairo-perf-trace benchmark results, and it did the job. Still TLB misses are a major problem for some operations with 2D graphics. Something like drawing a vertical scrollbar, where accessing each new scanline triggers a TLB miss with 4KiB pages. Or image rotation.
So what can be done?
The 32bpp color depth with 1920x1080 resolution on Allwinner A10 is quite unfortunate to hit this hardware quirk.
First a fantastic option :-) We could try to implement backwards solid fill in pixman and use it on the problematic hardware (using the icky /proc/cpuinfo text parsing to fish out the relevant bits of the information and do runtime detection). Still the problem does not go away, some other operations may be affected (memcpy is also affected, albeit to a lesser extent), memset is used in the other software, ...
We could also try the 24bpp color depth for the framebuffer. It provides the same 16777216 colors as 32bpp, but is much less affected as seen in table 1. A practical problem is that this is quite a non-orthodox pixel format, which is poorly supported by software (even if it works without bugs, it definitely does not enjoy many optimizations). This implies the use of ShadowFB with a 32bpp shadow framebuffer backing the real 24bpp framebuffer. But ShadowFB itself solves some problems and introduces new ones.
If your monitor supports the 50Hz refresh rate - just go for it! Additionally enabling the "scaler mode" surely helps (but wastes one scaled layer). The tricky part is that we want linux distros to remain user friendly and preferably still do automatic configuration. Automatic configuration means using EDID to check whether the monitor supports 50Hz. However the monitor manufacturers don't seem to be very sane and the EDID data may sometimes look like this:
[ 1133.553] (WW) NVIDIA(GPU-0): The EDID for Samsung SMBX2231 (DFP-1) contradicts itself: mode
[ 1133.553] (WW) NVIDIA(GPU-0): "1920x1080" is specified in the EDID; however, the EDID's
[ 1133.553] (WW) NVIDIA(GPU-0): valid VertRefresh range (56.000-75.000 Hz) would exclude
[ 1133.553] (WW) NVIDIA(GPU-0): this mode's VertRefresh (50.0 Hz); ignoring VertRefresh
[ 1133.553] (WW) NVIDIA(GPU-0): check for mode "1920x1080".The movie lovers seem to be also having some problems with 56Hz specified as the lowest supported. The use of 56Hz for some tests in table 1 is actually to see whether the 56Hz monitor refresh rate would be any good.
And as the last resort you can either reduce the screen resolution, or reduce the color depth to 16bpp. This actually may be the best option, unless you are interested in viewing high resolution photos with great colors and can't tolerate any image quality loss.
Final words
That's basically a summary of what has been already known for a while, and I kept telling this to people in the mailing lists and IRC. Intuitively, everyone probably understands that higher memory clock frequency must be somewhat better. But is it important enough to care? Isn't the CPU clock frequency the only primary factor that determines system performance? After all, it is the CPU clock frequency that is advertised in the device specs and is a popular target for overclockers. Hopefully the colorful tables and charts here are providing a convincing answer. In any case, if you are interested in FullHD desktop resolution on Allwinner A10, it makes sense to try your best to stay away from the "red zone" in table 1.
The performance of software rendering for 2D graphics is scaling very nicely with the memory speed increase on ARM processors equipped with a fast NEON unit (Cortex-A8, Cortex-A9, Cortex-A15). But the cairo-perf-trace benchmarks are only simulating offscreen rendering, which is just a part of the whole pipeline. The picture still needs to be delivered to the framebuffer for the user to see it. And it's better to be done without screw-ups.
To be continued about what's wrong with the ShadowFB layer.